If you are using AI agents in your workflows, some of them are not doing what you think they are doing. Not because they are broken. Because they quietly decided to do less.
There is no stack trace. No error log. No alert. Just slightly worse output that looks close enough to pass.
We know this because it happened to us.
What It Looks Like From the Outside
At Codenotary, we use AI agents across our entire development process: code review, QA, change analysis, automated checks. One day we noticed our automated reviews were completing faster than usual. The output looked fine at first glance, but edge cases were slipping through, style inconsistencies went unflagged. Things that used to get caught reliably.
The worst failures in AI agents are not crashes or exceptions. They are the ones where the agent quietly stops doing part of the work.
And if you are not watching closely, you will not even notice that one of them was never invoked.
This is a new class of failure. Not an error. Silence.
How We Actually Found It
AgentMon collects telemetry from every agent session on your machine and streams it to a central dashboard:
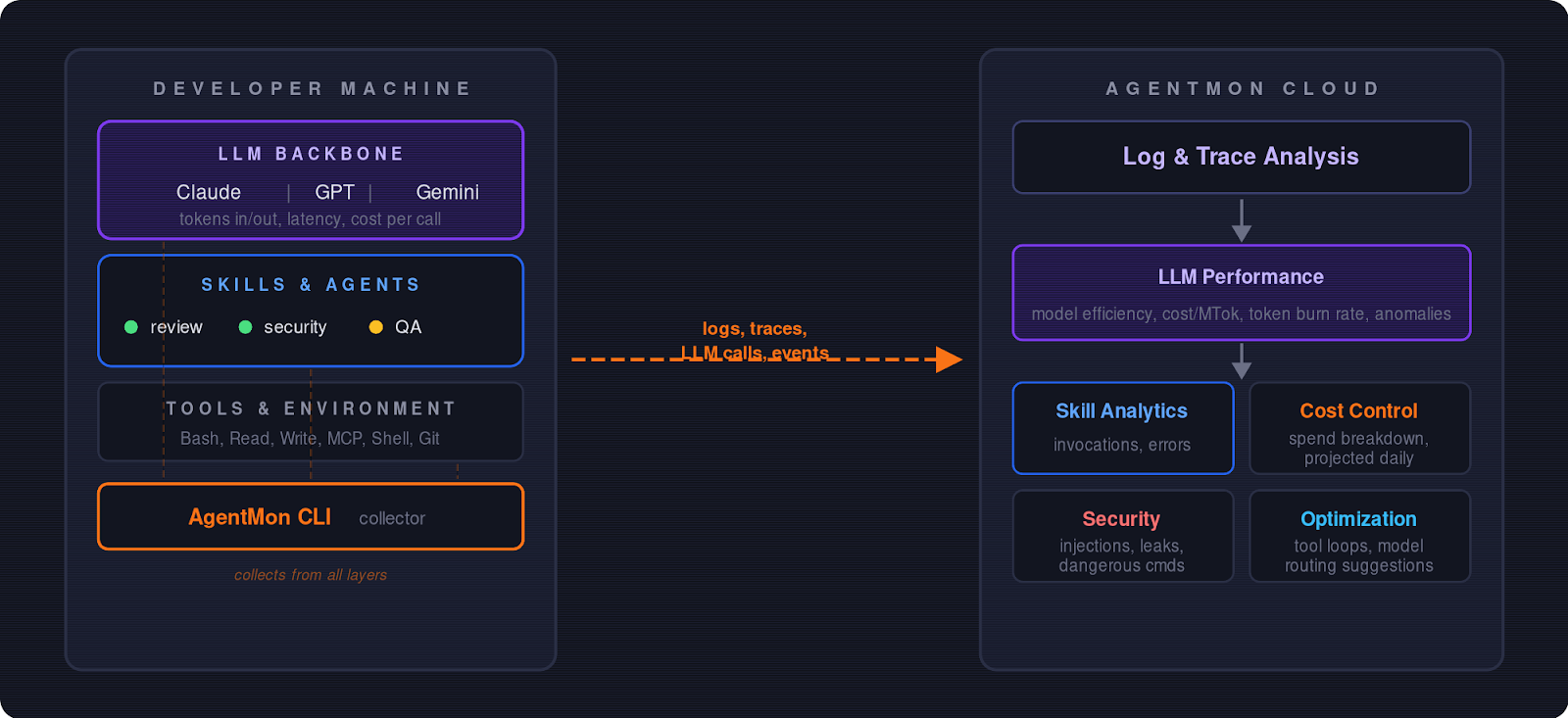
We opened the traces for the last review run, and the picture was obvious within a minute:
- primary review agent: invoked
- specialized code review agent: not invoked
- QA agent: not invoked
Two out of three agents were never invoked. The orchestrator had simply stopped calling them.
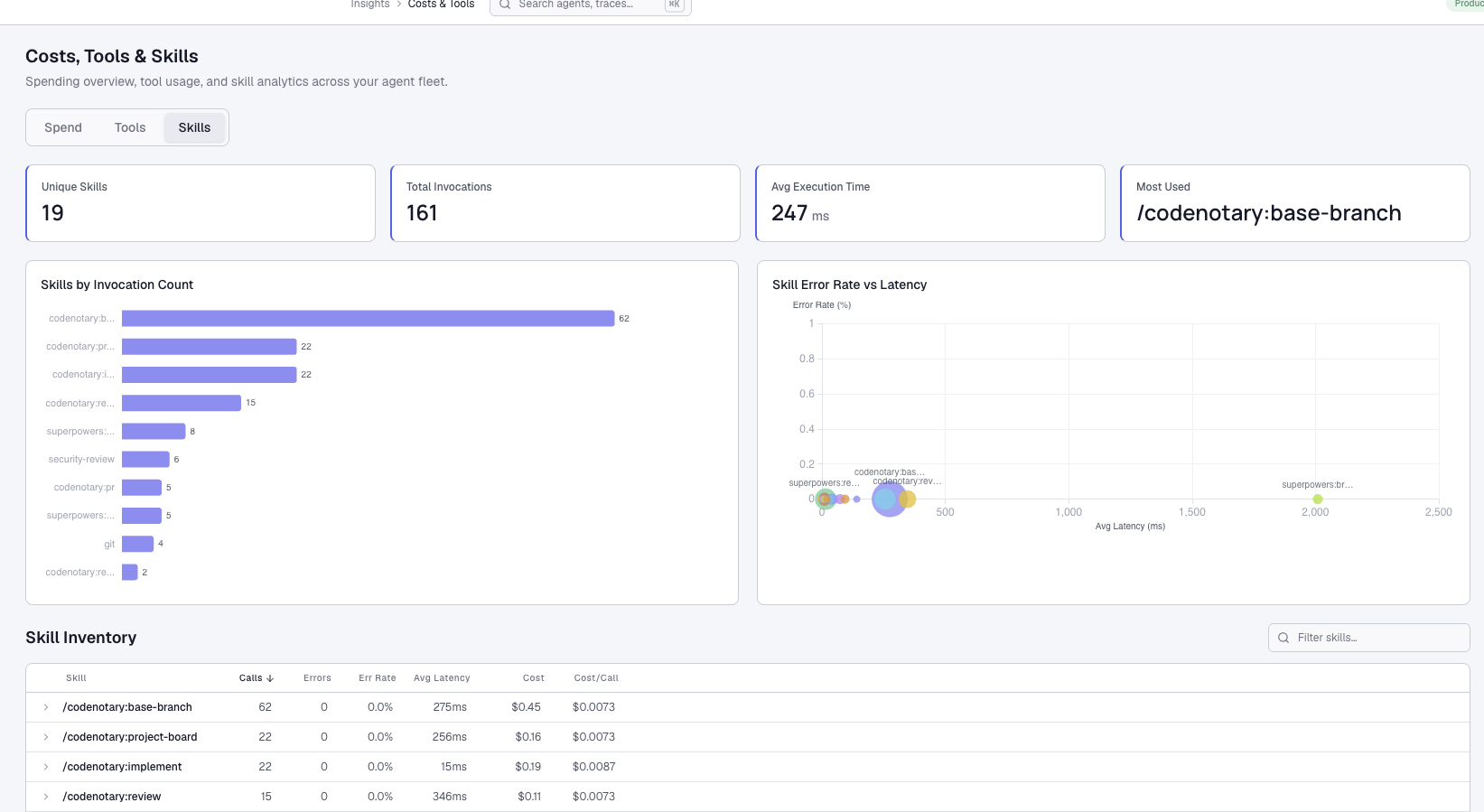
Why the Model Did This
The routing rules that determined when to delegate tasks to specialized agents had become too permissive. They were framed as suggestions rather than requirements.
The AI model treated them as optional. When it could produce a plausible-looking review without invoking the other agents, it simply did. The model chose the minimum viable path to complete the task rather than the thorough one. There was no bug in the traditional sense. The instructions just were not strict enough.
Before:
Run `codenotary:code-review` if available
After:
**MUST** invoke `codenotary:code-review` via the Skill tool
- Only if the Skill tool returns an error (skill not found),
fall back to reviewing
This Is Probably Happening to You Right Now
If you have AI agents in your workflow, you can technically verify all of this by hand. Open the console, scroll through the logs, reconstruct which agents were called. For a single run, that works. But when your team runs hundreds of agent sessions a day across multiple systems, reading raw terminal output is not a strategy. It is a gamble.
Ask yourself: can you tell which agents were actually invoked in your last automated review, and whether any steps were silently skipped compared to last week? If the answer is no, you already have this blind spot. You just have not found it yet.
Why This Matters for Software Integrity
At Codenotary, we believe in the immutability of code and the integrity of the supply chain. AI agents are now a part of that supply chain. If an agent silently skips a security check, your software’s integrity is compromised before the first line is even compiled.
Skipped steps are only one category of risk. But silent failures don’t stop at correctness — they extend into security. AgentMon also monitors for prompt injection attempts, credential leaks in agent I/O, and dangerous command execution, all of which are already live in the product and flagging real issues in our own environment.
OpenClaw, Devin, Cursor agents, Claude Code, custom LangChain workers: AI agents are multiplying across engineering infrastructure faster than teams can keep track of them. AgentMon gives you one place to see them all, control spend, and stop problems before they escalate, regardless of which framework or platform your agents run on.
Your agents are only as reliable as your ability to see what they actually do.