
AI agent risk monitoring is the practice of continuously evaluating every autonomous agent in your environment — what it has access to, what it actually does, and whether anyone has explicitly governed it — and turning that into a single fleet-wide posture you can act on. It is the discipline that closes the gap between “an agent crashed” and “an agent did something risky.” This post walks through what that gap looks like in practice, and how Codenotary’s AgentMon closes it.
Two days ago we counted: across a single test fleet, AgentMon was watching 1,843 agents, 4,714 sessions, six of which were “down” right now, and 432 in some kind of warning state.
Quick — which one is doing something it shouldn’t?
If you have to grep through logs to answer that question, you already have the only problem AgentMon was built to solve. This is part one of a four-part series. We’re going to walk through Risk, Security, Performance, and Cost — the four questions every team running AI agents at any non-trivial scale has to answer continuously, and the four lenses AgentMon gives you to answer them. We’ll do it the same way we run our own fleet: looking at the live amon-test environment, which is a synthetic-load workspace we keep online so customers can poke around without bringing their own data.
Why AI Agent Risk Monitoring Matters
A traditional ops view of an AI agent is: did it crash? AgentMon’s view is: did it do something risky? Those are different questions, and the gap between them is where things go wrong — exactly the gap NIST’s AI Risk Management Framework tells you to instrument.
An agent that crashed is loud. PagerDuty fires. Someone restarts the worker. Life goes on.
An agent that didn’t crash, but quietly skipped a security check, or burned through $400 of completions on the same backtrack loop, or wrote to a .env file nobody approved — that one is invisible until it becomes a Slack thread. And by the time it’s a Slack thread, you’re explaining it after the fact.
So when we talk about “AI agent risk monitoring,” we mean the superset: every behavior an agent exhibits that an auditor, a CISO, a finance lead, or a platform owner would want to know about. Not failures. Behaviors.
Fleet-Wide AI Agent Risk MonitoringRisk policy can be rolled ou
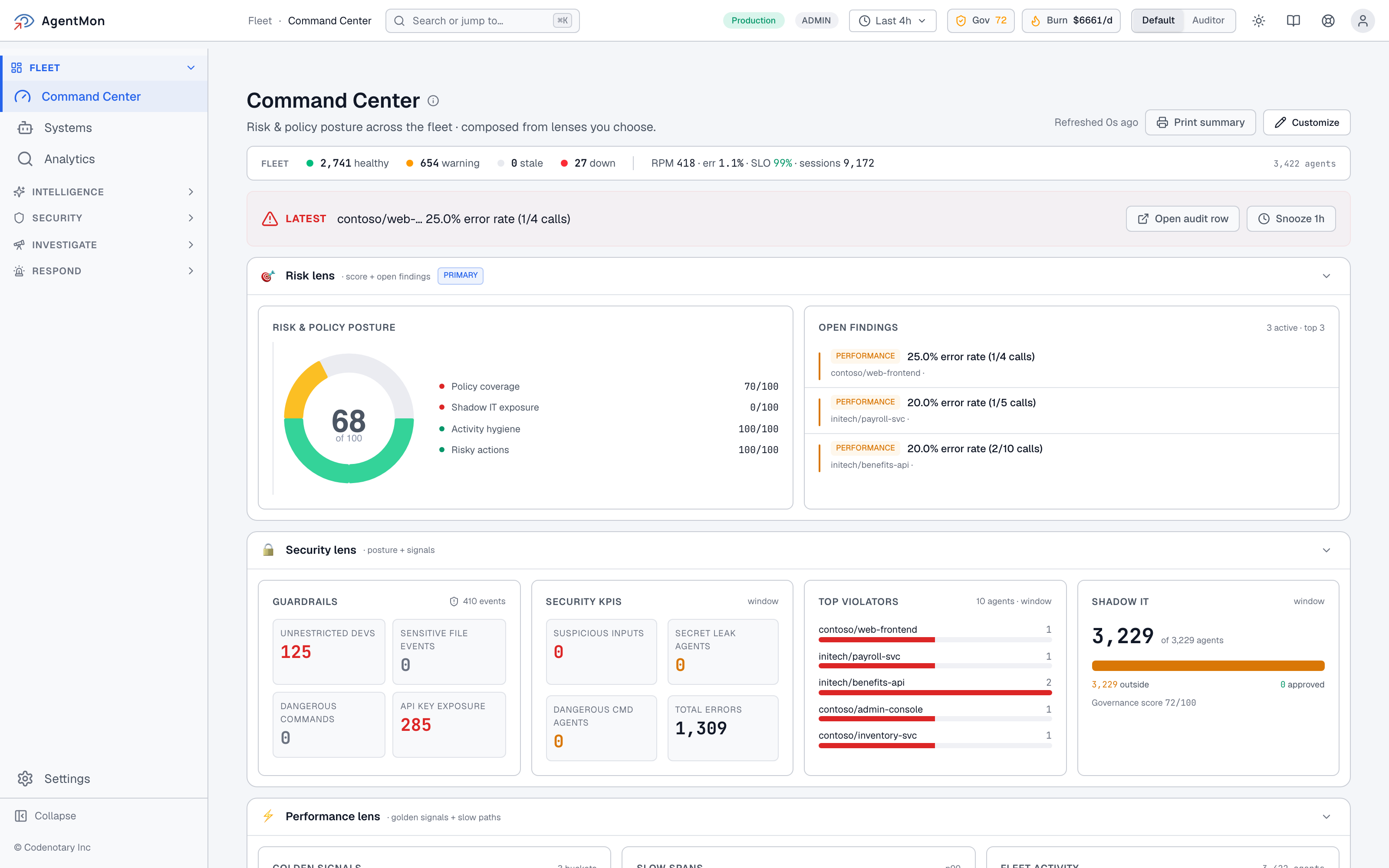
When you log into AgentMon, you land here:
A few things to notice on this screen before we even drill in:
The top strip is the fleet at a glance: 1,405 healthy agents, 432 warning, 6 down, plus rate-per-minute, error rate, SLO, sessions, and the active agent count. Nothing exotic. The point is that all 1,843 agents are surfaced in one number — not buried under five separate observability tools.
The header gauges in the corner — “Gov 100” and “Burn $4668/d” — are the two posture numbers we want a leader to be able to read at a glance. Governance score is high; burn rate is something you’d want to know about. (We’ll spend an entire post on that one in part four.)
And then the page itself is composed of lenses. Risk lens, Security lens, Performance lens. The lens model matters: instead of a one-size-fits-all dashboard, the Command Center lets you stack the views the role on call right now actually needs. A CISO and an SRE will look at the same fleet and care about almost completely different things — the Command Center lets them.
What the Risk Lens actually tells you
The Risk Lens scores the fleet on four dimensions and then surfaces the open findings underneath:
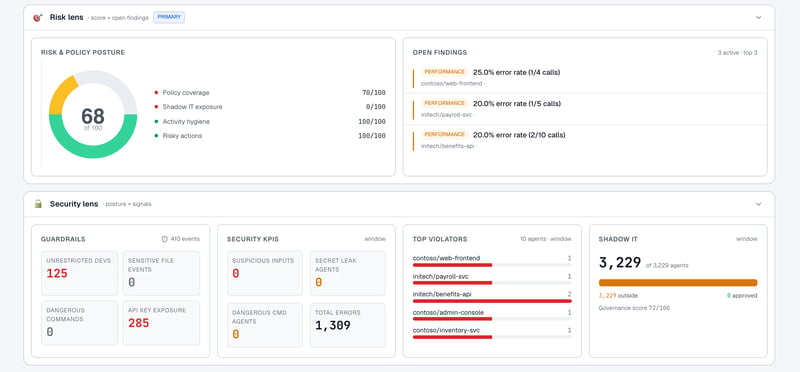
The score is a roll-up. The components are what a security or platform lead would actually act on:
- Policy coverage — is every agent in the fleet running under a policy at all? A zero here doesn’t mean you’re insecure; it means you haven’t told AgentMon what “secure” looks like yet for these agents. That’s a fixable problem, but you’d want to know it.
- Shadow IT exposure — how many agents are running on the fleet that nobody has explicitly governed? More on this in a second.
- Activity hygiene — how clean is the session telemetry itself? Are agents finishing their work, or leaving sessions open for 24+ hours?
- Risky actions — over the time window, how many agents triggered something the platform considers dangerous: a dangerous shell command, a write to a sensitive file, an API key in a tool call?
The other side of the Risk Lens is what we call Open Findings — currently three of them, all classified PERFORMANCE, each pinned to a specific agent and showing the exact symptom (20.0% error rate on 1/5 calls for initech/timesheets). One click, you’re at the trace. Two clicks, you’re at the span. That is the Two-Click Drill-Down in the AgentMon product spec, and it is the single most important UX commitment in the platform: never make a responder context-switch between tools to answer “what actually happened?”
Shadow AI is its own category of risk
Agents proliferate. Of course they do — they’re trivially easy to spin up. A developer trying a new framework, a vendor agent attached to a SaaS tool, an internal proof-of-concept that quietly went to production: every one of those is a sanctioned-or-unsanctioned decision your governance team almost certainly didn’t make explicitly. That’s the shadow AI problem, and it’s the fastest-moving piece of any AI agent risk monitoring program.
AgentMon’s Shadow IT Discovery page exists for exactly this:
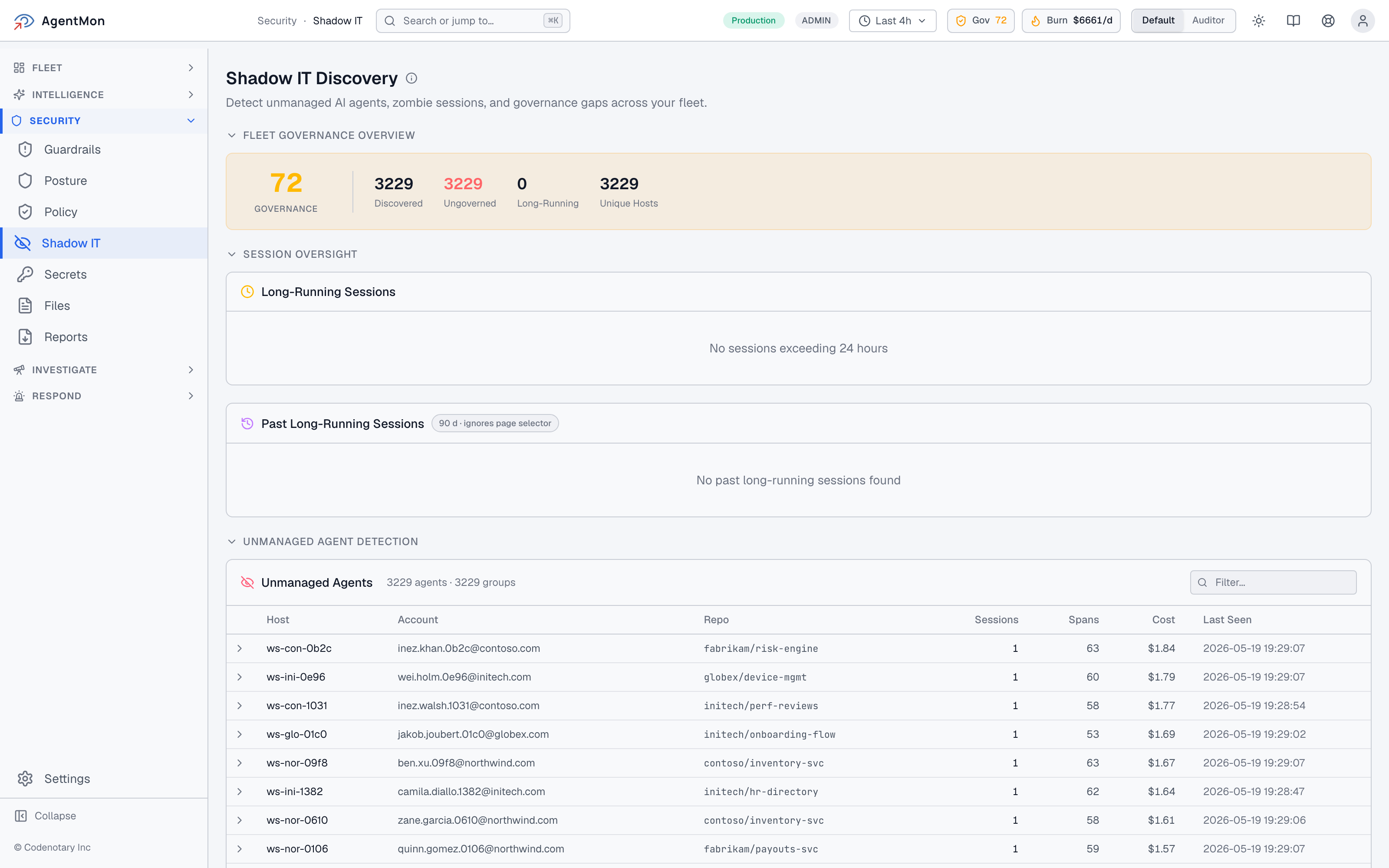
Three things this page answers that nothing else really does:
The Fleet Governance Overview is the rolling answer to “are there agents running here that nobody has signed off on?” In our synthetic environment everything is governed, but a real fleet will show a number, and that number is the lead indicator of unmanaged AI agent risk.
Session Oversight catches the other side of the same coin: sessions that have been running longer than 24 hours. Long-running sessions are not always bad — but they are always interesting. An agent that has been alive for three days has either finished its job and forgotten to exit, or has been retrying the same step in a loop, or is doing something nobody planned for.
The Shadow Risk Leaderboard ranks accounts by their personal contribution to fleet risk. This is the artifact your governance leads want to walk into a quarterly review with: not “the platform is unsafe,” but “anya.kowalski on ws-fab-0713 is ungoverned across 10 agents at an estimated $3.16/run — let’s get her onboarded.”
Risk policy: the soft-launch lane
A common objection to all of this is: fine, you can see the risk, but if you start blocking things you’ll break my engineering team. Codenotary’s view is that policy enforcement has to roll out the way Linux firewalls roll out — by default, in dry-run, and only graduating to “enforce” once you’ve watched it for thirty days.
AgentMon’s policy engine is built on Rego, evaluated locally at the PreToolUse hook, and exposes the simulated state separately from the enforced state:
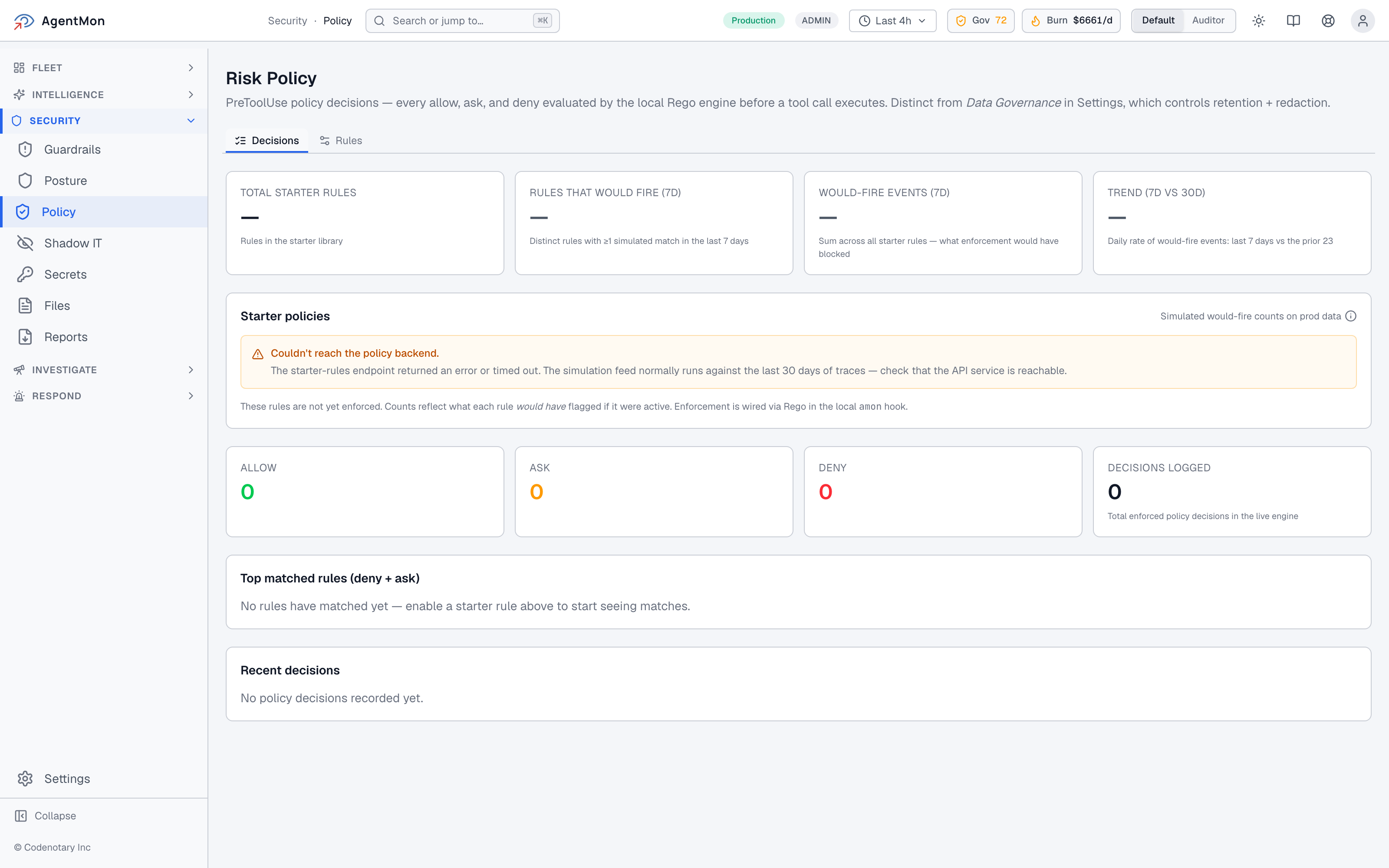
Two things to call out on this view: the top half is the “what would happen if I turned this on?” view (Rules That Would Fire, Would-Fire Events, plus the 7d-vs-30d trend), and the bottom half is the “what actually happened?” view (live ALLOW / ASK / DENY counts in the enforcement engine).
That separation matters. It means you can ship a new rule into production knowing exactly how many times it would have fired against the last 30 days of trace data before you flip it from would-fire to fire. No mystery rollouts.
What AgentMon measures, in one sentence
AI agent risk monitoring, in AgentMon’s vocabulary, is the answer to: for everything running in the fleet right now, does someone know about it, is it doing what it was meant to do, and would we be able to prove it to an auditor?
If the answer to any of those three is no, AgentMon will tell you why — pinned to a specific agent, a specific session, and a specific span — before the conversation gets to the conference room. Open findings, governance score, shadow AI inventory, simulated and enforced policy, long-running session detection: these are not five separate features. They are five views onto the same question.
If you can’t see what your agents are doing, you can’t manage what they’re doing. Risk is what happens in that gap.
Frequently asked questions about AI agent risk monitoring
What is AI agent risk monitoring?
AI agent risk monitoring is the continuous practice of evaluating every autonomous agent in your environment for governance posture, behavior, and exposure — and rolling those signals up into a fleet-wide score that a CISO or platform lead can act on. It is not the same as agent crash monitoring or APM; the failures it catches are usually silent.
How is AI agent risk different from traditional application risk?
Traditional application risk assumes the application does what it was coded to do. AI agents make decisions at runtime — what tools to call, what files to read, what commands to run — so the risk surface is the behavior space, not the codebase. You can’t audit it by reading source; you have to observe it.
What does a “shadow AI” finding look like in AgentMon?
A shadow AI finding is any agent running in the fleet that isn’t covered by a governance policy. AgentMon discovers them passively from the local Claude / Codex config on each developer machine, plus from agent telemetry, and ranks them on a Shadow Risk Leaderboard so you can prioritize onboarding the highest-risk ones first.
Can I run AgentMon in simulation mode before enforcing policies?
Yes — every policy ships with a simulated state and an enforced state. You can write a Rego rule, watch it against the last 30 days of trace data to see how many times it would have fired, and only flip it to enforce once you’re comfortable with the would-fire rate.
Next in the series: AI Agent Security: Stop Prompt Injection and Secret Leaks. We’ll go a level deeper into the Security Lens, the Guardrails dashboard, the Posture page, and the parts of the platform that exist specifically to stop your agents from leaking your secrets or running curl | sh in production.
Start with AgentMon — free · See the product · Further reading: OWASP Top 10 for LLM Applications